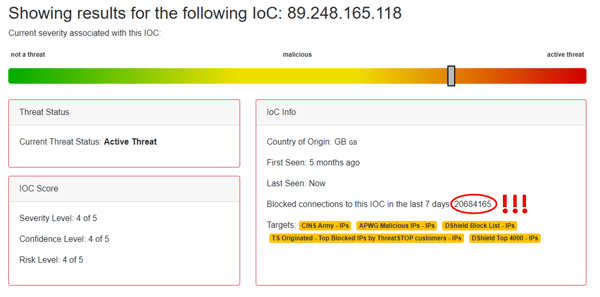
<span id="hs_cos_wrapper_post_body" class="hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_rich_text" style="" data-hs-cos-general-type="meta_field" data-hs-cos-type="rich_text" ><p style="text-align: justify;">Everyone knows you need to block the bad stuff from getting onto your network and calling home to its masters. But what happens when something good gets incorrectly flagged as malicious? A false positive (FP) if managed poorly can be almost as bad as letting something potentially dangerous get through.</p> <p style="text-align: justify;"><!--more--></p> <p style="text-align: justify;">FPs can result in lost traffic and revenue for the wrongfully accused, wasting time and resources for those investigating and resolving the issue. In a study conducted by ESG Research, most security, IT, and DevOps leaders say their organization spends an equal amount, or more, time on false positives as on legitimate attacks. When FPs become a recurring problem, you start to lose trust. Is this IP <em>really</em> good? Is that IP <em>really</em> bad? Too often, the result ends up being over investigation or a lapse in standards.</p> <p style="text-align: justify;">Drastic breaks in service can also be a potential result of FPs. <span style="background-color: transparent;">An extreme example (that has happened without any fatalities) is a hospital using a SAAS paging service. This paging service was hosted on an IP that was simultaneously hosting multiple phishing sites. With this, the pager service didn’t work until they added that IP to their custom whitelist. Is the potential risk of blocking something good worth the extreme vulnerability to malware and attacks that comes with underblocking?</span></p> <p style="text-align: justify;"><span style="background-color: transparent;">Stay with us for a bit and we'll answer that question together.</span></p> <h2 style="text-align: justify; font-weight: bold;">Many routes to a False Positive</h2> <p style="text-align: justify;">The most common source of FPs is human error. Analysts at threat intelligence providers tend to have a bias towards blocking, as threat removal is often difficult. Faulty algorithms are an additional source of FPs. Many companies use machine learning and data mining to find malicious addresses that are not always 100% accurate.</p> <p style="text-align: justify;">Another frequent cause of FPs is when companies self-list through misconfiguring auto-protection services such as DenyHosts. If DenyHosts are misconfigured not to exclude reporting of their own IP addresses (especially their system monitoring servers), an organization’s own DenyHosts can send their IP addresses to the shared database, locking themselves out.</p> <p style="text-align: justify; font-weight: normal;">While some infrastructure is born malicious (such as <a href="/is-dns-the-key-to-dga-protection" rel="noopener">C2 DGA domains</a> and <a href="/watch-out-for-this-bad-ip" rel="noopener">sketchy hosting providers</a>), it's more common for legitimate infrastructure to be compromised and exploited for malicious purposes. Because of this, false positives often occur if the IP or domain that was previously serving up malicious traffic has since been cleaned up, but has not aged off the data source in question. If reputational services do not constantly update their lists based on the current threat infrastructure landscape, they are likely to contain many FPs.</p> <h2 style="text-align: justify; font-weight: bold;">One man's spammer is another man's customer</h2> <p style="text-align: justify;">A more complex FP situation is when malicious content is served from one URL (or a couple) living on an IP address that hosts thousands of other domains as well. The innocent sites stuck in a bad neighborhood. For instance, the TLD .tk has earned itself a bad reputation from the large amounts of malicious domains and spam that it hosts. Yet .tk also hosts the Tcl Developer Xchange (tcl[.]tk), a popular and legitimate service that is most likely blocked by many because of its bad neighbors. In these examples, it’s not so much a false positive as not having the correct level of granularity to deal with multi-hosts. Basically, any critical service that’s connected through a shared public IP has the potential of being blocked in a false positive.</p> <h2 style="text-align: justify; font-weight: bold;">Block More, Use Granular Protection, Respond Quickly</h2> <p style="text-align: justify;">When you go to Disneyland with your family and that super cool ride that your kids love is closed for maintenance, it can definitely be a big disappointment. But no one would want the ride to stay open if there is suspicion that it is faulty, especially when the price can be a serious injury - or worse. The same caution should be taken in cyber security. The cost of underblocking and enduring a cyber attack or ransomware infection is so high at this point, that the bias has to change towards staying safe from as many threats as possible. But - that does not mean "block everything, all the time".</p> <p style="text-align: justify;">Many well-known threat feeds are more generic than one realizes, providing a one-size-fits-all solution. As we all know, one size definitely does not fit all in this industry, and every organization has its own needs. The result of this solution approach - no customizability, neither in adding IOCs you want to block for your organization's specific needs, and nor in dynamically unblock IOCs you need to be accessing right now. You should to be able to easily and dynamically whitelist indicators that need to be unblocked ASAP. No waiting hours or even days for the support team to help you out, no tedious manual changes of BIND configurations. We're talking about an instant policy change with rapid propagation for actual operational responsiveness. <span style="font-weight: bold;">That's what ThreatSTOP does.</span></p> <p style="text-align: center;"><em>Ready to try ThreatSTOP in your network? Want an expert-led demo to see how it works?</em></p> <p style="text-align: center;">&nbsp; &nbsp; &nbsp; &nbsp;</p> <p style="text-align: center;">&nbsp;</p></span>

![Bad Domain of the Week: D-D-Don't mess with ddd[.]com](https://www.threatstop.com/hs-fs/hubfs/ddd.png?width=600&name=ddd.png)